随着人工智能大模型训练与推理需求的爆发式增长,AI 算力正以远超摩尔定律的速度狂飙。然而,在这场算力军备竞赛的背后,一个隐形的瓶颈正逐渐浮出水面 —— 散热。当单 GPU 芯片功耗突破 1400W,单机柜功率攀升至 120kW,传统的风冷技术早已触及物理天花板。在这一背景下,相变降温材料(Phase Change Material, PCM)凭借其独特的潜热储能特性,正在从芯片级到数据中心级,为 AI 行业构建起一套全新的热管理体系,成为突破 “功耗墙” 与 “热障壁” 的关键钥匙。
一、解密相变降温材料:会 “吸放热” 的温度平衡大师
要理解相变材料为何能成为 AI 散热的救星,首先需要了解其核心工作原理。相变降温材料是一类能够在特定温度区间内,通过自身物态的变化(通常是固态到液态)来吸收或释放大量潜热的功能性材料。
与传统的散热材料仅依靠显热(即温度升高来吸收热量)不同,相变材料在相变过程中,温度几乎保持恒定,却能吸收远超显热的能量。例如,常见的石蜡类相变材料,其熔化潜热可达 200-250 kJ/kg,这意味着 1 公斤的石蜡在熔化时,能够吸收相当于 2 公斤水升高 30 度所吸收的热量。

图 1: 应用于电子器件的相变导热垫片,常温下为固态,受热后软化填充界面间隙并吸热
这一特性使得相变材料成为了天然的 “热量缓冲器”:当 AI 芯片高负载运行、温度急剧升高时,PCM 会迅速熔化,像海绵吸水一样将多余的热量储存起来,从而抑制温度的飙升,避免芯片因过热而降频;而当负载降低、温度回落时,PCM 又会凝固,将储存的热量缓慢释放出来,从而平抑温度的波动,让芯片始终工作在最优的温度区间。
二、AI 算力的 “高烧” 困境:传统散热已无力回天
在 AI 技术飞速发展的今天,散热早已不再是一个可有可无的配套设施,而是直接决定了算力上限与运营成本的核心瓶颈。
1. 功耗密度的指数级爆炸
过去十年间,AI 芯片的功耗经历了恐怖的飞跃。从早期的 150W GPU,到如今英伟达 Blackwell 架构的 B200 芯片,单芯片功耗已经突破了 1400W,下一代 Rubin 架构更是直指 2300W。与之对应的,数据中心单机柜的功率密度也从传统的 10kW,迅速攀升至 50kW、100kW,甚至 120kW。
这给传统的风冷散热带来了灭顶之灾。空气的导热能力极其有限,传统风冷的散热极限大约在 30kW / 机柜,一旦超过这个阈值,风扇就算开到最大,也无法及时将热量带走。这就导致了一个恶性循环:为了压温,数据中心不得不把空调开得极低,这又进一步推高了能耗。
2. 能耗与寿命的双重代价
据统计,在当前的 AI 数据中心中,散热系统的能耗已经占到了总能耗的 40% 以上。这意味着,你花 1 块钱买电跑 AI 模型,其中有 4 毛钱是用来给机器降温的。这不仅极大地推高了算力成本,也与 “双碳” 目标背道而驰。
更严重的是,高温正在严重透支 AI 硬件的寿命。根据半导体可靠性理论,温度每升高 10℃,芯片内部的电迁移速率就会翻倍,这意味着硬件的老化速度会指数级增加。同时,AI 训练任务的脉冲式负载导致的温度剧烈波动,还会引发热机械应力,导致焊点疲劳、芯片脱层,最终引发硬件故障。微软、谷歌等巨头的运维数据显示,过热导致的降频与宕机,已经成为影响 AI 集群稳定性的头号杀手。
三、从芯片到机房:相变材料的全栈式散热革命
面对这一困境,相变降温材料正在 AI 行业的各个层级落地应用,从最底层的芯片界面,到整个数据中心的制冷系统,构建起了一套全栈式的散热解决方案。
1. 芯片级:瞬态热冲击的 “缓冲垫”
在最微观的芯片层面,相变材料主要作为高性能的热界面材料(TIM)使用。传统的导热硅脂虽然能填充芯片与散热片之间的间隙,但面对 AI 芯片瞬间的脉冲式发热,往往反应不及。
而高导热相变材料则完美解决了这一问题。它在常温下是固态的垫片,方便安装;当芯片温度升高到相变点(通常是 45-55℃)时,它会迅速软化,完美填充界面的微观缝隙,将界面热阻降到极致。同时,它的潜热特性可以瞬间吸收掉芯片爆发出来的热量,就像给芯片装上了一个 “温度缓冲垫”。
在某大型云服务企业的 AI 算力集群中,他们将 10000 台服务器的导热材料全部替换为相变材料。结果显示:
- 数据中心 PUE 值从 1.65 大幅降至 1.42,每年仅制冷能耗就节省 320 万元;
- 服务器平均故障间隔时间(MTBF)从 8000 小时延长至 12000 小时,故障率降低了 33%;
- 单位面积算力密度提升了 25%,意味着在不扩建机房的情况下,就能容纳更多的 AI 服务器。
2. 机柜级:浸没相变液冷的极致能效
当单机柜功率突破 100kW,仅仅在芯片上做文章已经不够了。这时候,整机浸没式相变液冷成为了终极解决方案。
这种方案的核心,是将整台服务器完全浸没在特殊的氟化液中。这种液体不导电、化学稳定,而且沸点很低(通常在 40-60℃之间)。当 AI 芯片开始发热时,紧贴芯片的氟化液会瞬间沸腾汽化,这个相变过程会吸收巨量的潜热,直接将芯片的热量带走。而汽化后的蒸汽上升到机柜顶部,遇到冷凝管又会液化成液体,回流到底部,完成一个自然的循环。
图 2: 规模化部署的浸没式液冷机柜,服务器整机浸入相变冷却液中
中科曙光在雄安数据中心部署的新一代相变浸没液冷方案,就是这一技术的典型代表。该方案实现了惊人的效果:
- PUE 值低至 1.05,这意味着几乎所有的电都用在了计算上,制冷损耗微乎其微;
- 芯片表面温度稳定在 60℃以下,温度波动控制在 ±0.5℃,彻底消除了局部热点;
- GPU 集群可以 24 小时持续满负荷运行,某 AI 实验室的大模型训练任务完成时间因此缩短了 25%;
- 单机柜年节省电费超 10 万元,设备故障率较传统冷板式液冷降低了 60%。
为了更直观地展示不同散热方案的差异,我们对传统风冷、冷板式液冷和相变浸没液冷的核心指标进行了对比:
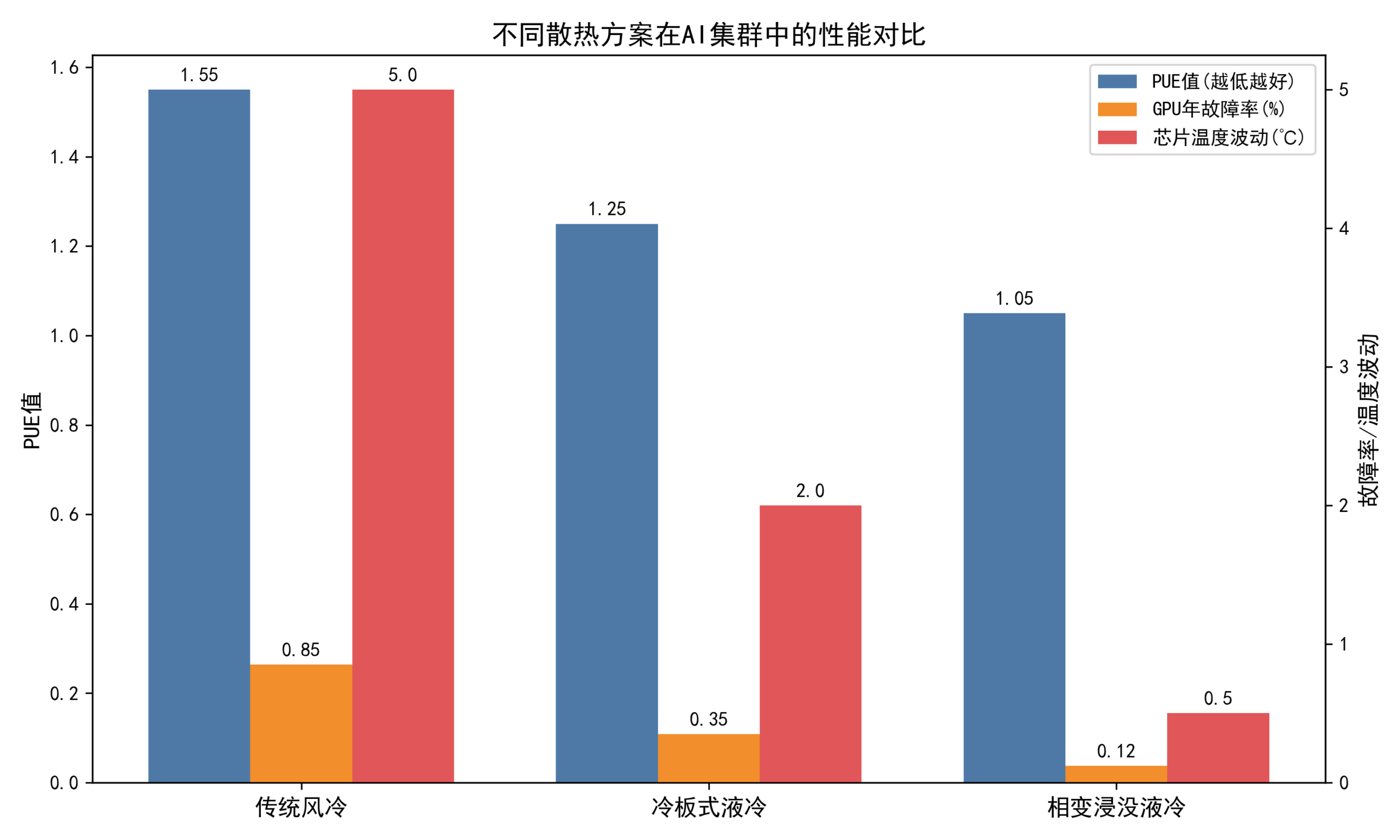
图 3: 不同散热方案在 AI 集群中的性能数据对比
从图中可以清晰地看到,相变浸没液冷在 PUE、故障率控制以及温度稳定性上,都全面碾压了传统方案。这也是为什么它被称为下一代 AI 数据中心的标配。
3. 光模块:高速互联的 “冷静剂”
除了算力核心的 GPU,AI 算力的另一个瓶颈 —— 高速光模块,也正在成为相变材料的新战场。
随着 AI 集群带宽需求的激增,光模块正在从 800G 向 1.6T、3.2T 加速迭代。随之而来的是光模块功耗的飙升,以及 CPO(共封装光学)等新型封装技术带来的超高热流密度。传统的散热方案已经无法解决激光器芯片的局部过热问题,这直接导致了高端光模块的产能缺口。
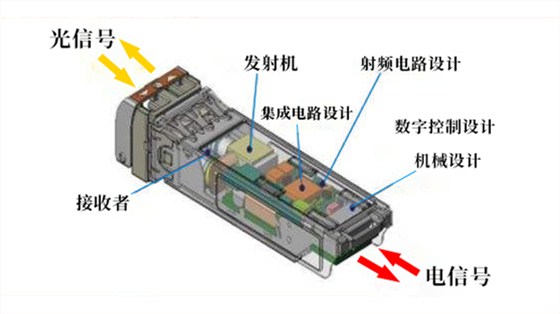
图 4: 高速光模块内部结构,相变材料被用于解决激光器芯片的热点问题
以飞荣达为代表的厂商,开发了专门针对光模块的高导热相变材料。这种材料可以紧贴激光器芯片,在极小的空间内快速吸收热量,将光芯片的结温降低 5-10℃,同时大幅提升温度的均匀性。这不仅解决了 1.6T 光模块的散热卡脖子问题,还显著延长了光器件的寿命,为 AI 算力的高速互联扫清了障碍。
四、技术演进:下一代相变散热的无限可能
目前,相变材料在 AI 领域的应用才刚刚起步,学术界和产业界正在不断突破其性能边界,未来的发展空间极其广阔。
一方面,是复合相变材料的研发。传统的有机相变材料导热系数较低,研究人员正在通过添加石墨烯、膨胀石墨、碳纳米管等高导热填料,来提升其热响应速度。例如,最新的研究已经制备出了导热系数高达 11.52 W/(m・K) 的复合相变材料,这比传统石蜡提升了几十倍,同时还保持了 227 J/g 的超高潜热。实验显示,这种材料可以将芯片的临界过热时间延长 4670 秒,最高降温幅度达到 20.4℃。
另一方面,是微胶囊化技术。通过将相变材料包裹在微小的胶囊里,可以彻底解决液态泄漏的问题,使得 PCM 可以像涂料一样涂在芯片表面,甚至添加到冷却液中,形成 “相变流体”,进一步提升液冷系统的热容。
更令人期待的是,AI 与相变散热的结合。未来的智能热管理系统,可以利用 AI 预测大模型训练的负载波动,提前调控相变材料的储放热过程,实现 “主动控温”,从而在极致能效下,释放出最大的算力潜力。
结语
在 AI 算力狂奔的时代,我们往往只关注芯片的算力、显存的带宽,却忽略了那个默默支撑这一切的 “隐形英雄”—— 散热。相变降温材料的出现,不仅仅是给 AI 芯片降了温,更是打破了制约算力增长的物理瓶颈,降低了算力的成本,延长了硬件的寿命。
从芯片界面的微小垫片,到浸没机柜里的沸腾液体,相变材料正在用最朴素的物理原理,重构着 AI 基础设施的热管理逻辑。我们有理由相信,随着材料技术的不断进步,相变降温材料必将成为 AI 时代的 “冷静基石”,支撑着人工智能向着更高、更远的未来迈进。
No responses yet